728x90

제출 디렉토리
- ex00/
제출해야 하는 파일
- Makefile 및 모든 필요한 소스 코드 파일
허용된 함수
- write, malloc, free, open, read, close
과제 설명
- 프로그램은 숫자를 입력받아 해당 숫자를 문자로 변환하여 출력해야 한다.
- 실행 파일 이름: rush-02
- 컴파일 방법:
- make fclean make
프로그램 실행 방식
- 인자가 1개일 경우
- 입력된 숫자를 문자로 변환하여 출력한다.
- 인자가 2개일 경우
- 첫 번째 인자는 새로운 참조용 사전(dictionary) 파일이며,
- 두 번째 인자는 변환할 숫자이다.
- 예외 처리
- 입력값이 양의 정수가 아닐 경우, "Error"를 출력하고 개행(\\n)해야 한다.
- unsigned int(4,294,967,295) 이상의 범위도 처리해야 함
사전 파일 (dictionary) 규칙
- 사전 파일은 프로그램의 숫자 변환에 사용되는 데이터 파일이다.
- 사전 내 데이터는 아래와 같은 형식을 따라야 한다.
- 숫자는 atoi(정수 변환 함수)로 변환될 수 있는 형식이어야 한다.
- : 앞뒤의 공백은 제거해서 사용해야 한다.
- [숫자][0~N개의 공백]:[0~N개의 공백][출력할 문자]\\n
- 사전 파일의 추가 규칙:
- 사전에는 기본적으로 제공되는 기본 키 값들이 반드시 포함되어야 한다.
- 단, 기본 키의 값은 변경 가능하다.
- 새로운 키를 추가하는 것은 가능하지만, 기본 키를 삭제할 수 없다.
- 이 경우, ./rush-02 20을 실행하면 hey everybody !를 출력해야 한다.
- 20 : hey everybody !
- 사전 파일의 오류 처리
- 파싱 오류 발생 시: "Dict Error\\n" 출력
- 사전에 값이 부족해서 숫자를 변환할 수 없을 경우: "Dict Error\\n" 출력
예제 실행 결과
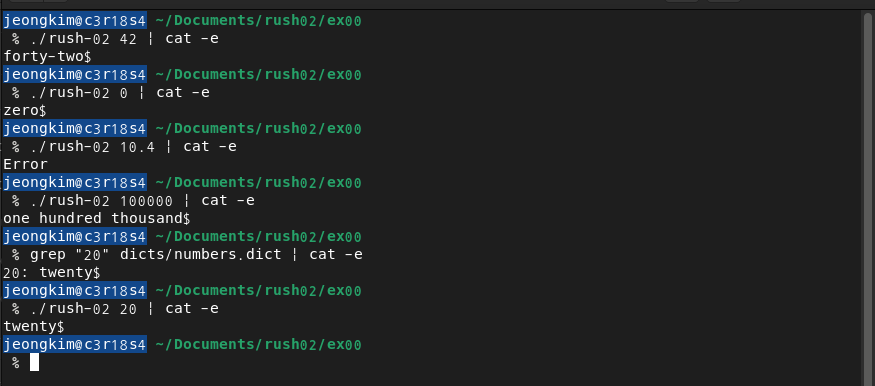
$> ./rush-02 42 | cat -e
forty two$
$> ./rush-02 0 | cat -e
zero$
$> ./rush-02 10.4 | cat -e
Error$
$> ./rush-02 100000 | cat -e
one hundred thousand$
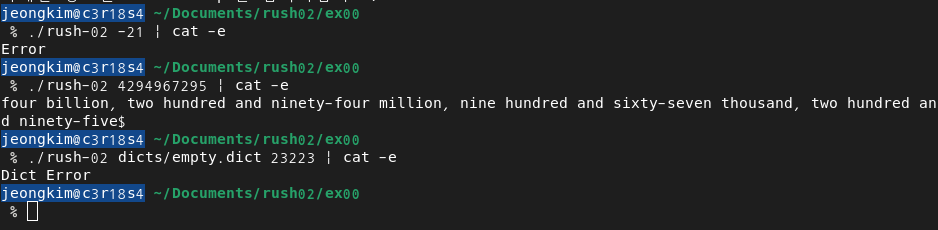
$> grep "20" numbers.dict | cat -e
20 : hey everybody !$
$> ./rush-02 20 | cat -e
hey everybody !$
추가 (보너스 기능)
- space, -, ,같은 문법을 활용해 더 자연스러운 문장 구조 만들기
- 다른 언어(프랑스어, 독일어 등)로 변환하는 기능 추가 (새로운 사전 파일 제공 가능)
- 프로그램 실행 시 입력값이 없을 경우, read를 사용하여 표준 입력에서 값을 읽도록 구현
폴더 구조
rush-02/
├── Makefile
├── dicts/
│ ├── fr.numbers.dict
│ └── numbers.dict
├── includes/
│ └── ft_header.h
├── rush-02
├── sources/
│ ├── main.c
│ ├── process/
│ │ ├── ft_check_args.c
│ │ ├── ft_free.c
│ │ ├── ft_print1.c
│ │ ├── ft_process.c
│ │ ├── ft_check_dict.c
│ │ ├── ft_parse_dict.c
│ │ ├── ft_print2.c
│ │ └── ft_split_by_three.c
│ └── utils/
│ ├── ft_condition.c
│ ├── ft_putstr.c
│ ├── ft_strcmp.c
│ ├── ft_putchar.c
│ ├── ft_split.c
│ └── ft_strlen.c프로그램 주요 로직은 process 에 구성
기타 유틸 파일은 utils에 구성
프로그램 실행 진입 파일은 main.c 파일
헤더는 includes 파일
로직 처리 함수 정리 표
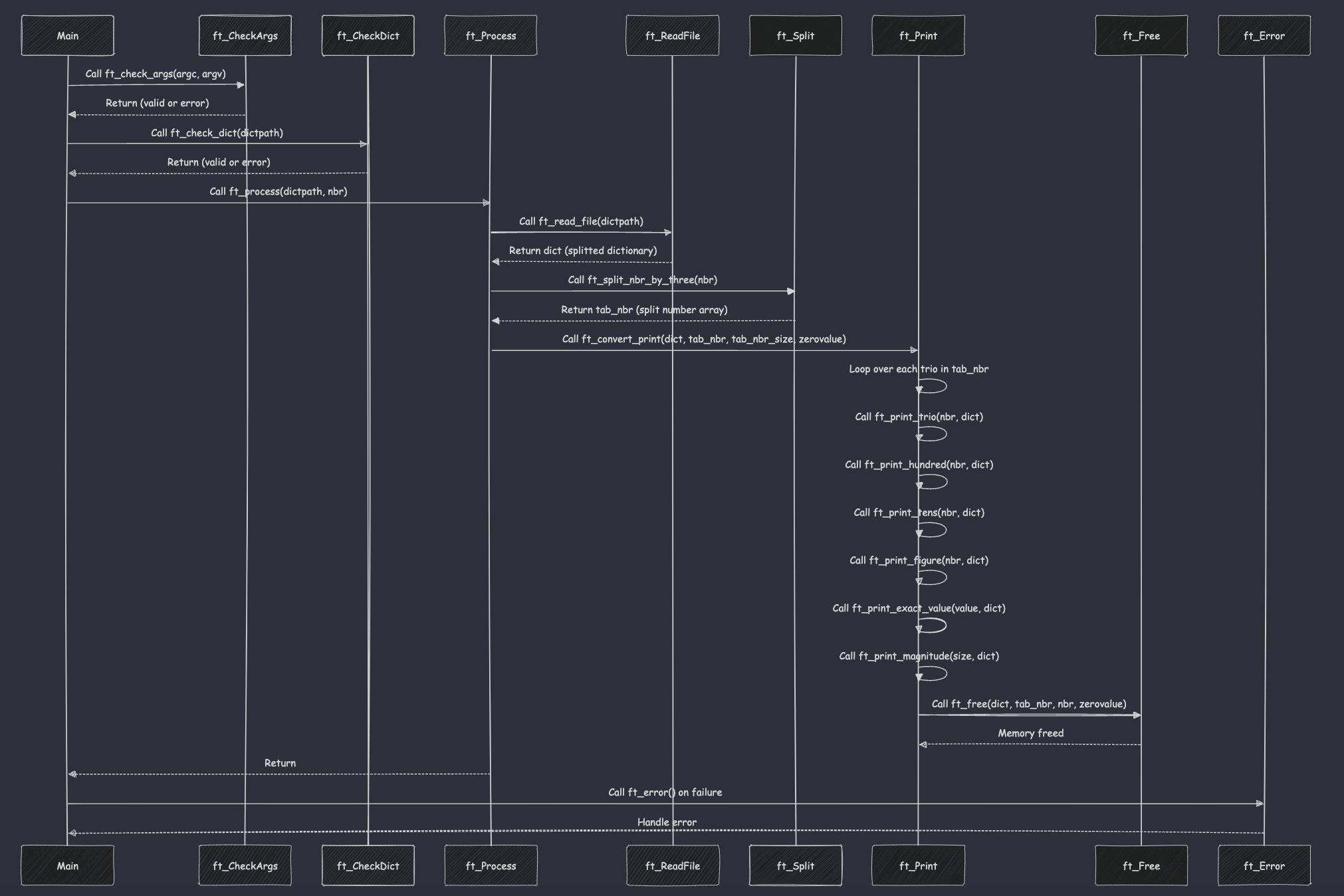
코드 실행 흐름
1. `main` 함수 실행 흐름
| 단계 | 함수/작업 | 설명 | 결과 |
|------|------------------------------------|-------------------------------------------------------------------|--------------------------------------------------------------|
| 1 | `main` 함수 시작 | 프로그램의 시작점. `dictpath`와 `nbr` 변수 선언. | - |
| 2 | `ft_check_args(argc, argv, ...)` | 인자(`argc`, `argv`)를 확인하여 `dictpath`와 `nbr` 값을 설정. | - |
| 3 | `ft_check_dict(dictpath)` | 사전 파일이 존재하고 크기가 유효한지 확인. | 존재하지 않으면 `"Dict Error"` 출력 후 종료 (`free(nbr)`) |
| 4 | `ft_process(dictpath, nbr)` | 숫자 문자열(`nbr`)을 처리하고 결과를 출력. | 실패 시 `"Dict Error"` 출력 후 종료. |
2. `ft_check_args` 함수
| 단계 | 함수/작업 | 설명 | 결과 |
|------|-----------------------------------|-------------------------------------------------------------------|--------------------------------------------------------------|
| 1 | `ft_check_nbr(argv[2])` | 숫자 인자가 유효한지 확인. | 유효하지 않으면 `0`을 반환하여 `"Error"` 출력 후 종료. |
| 2 | `ft_is_contain_number(argv[2])` | 문자열에 숫자가 포함되어 있는지 확인. | 숫자가 없으면 `0`을 반환. |
| 3 | `ft_strlen(argv[2])` | 문자열의 길이를 반환. | `argv[2]`의 길이를 반환. |
| 4 | `ft_is_whitespace(nbr[i])` | 문자가 공백인지 확인. | 공백 문자일 경우 `1` 반환. |
3. `ft_check_dict` 함수
| 단계 | 함수/작업 | 설명 | 결과 |
|------|-----------------------------------|-------------------------------------------------------------------|--------------------------------------------------------------|
| 1 | `ft_get_file_size(dictpath)` | 파일 크기를 구하기 위해 파일을 열고 크기를 계산. | 파일이 존재하지 않으면 `-1` 반환, 존재하면 파일 크기 반환. |
4. `ft_process` 함수
| 단계 | 함수/작업 | 설명 | 결과 |
|------|-----------------------------------|-------------------------------------------------------------------|--------------------------------------------------------------|
| 1 | `ft_read_file(dictpath)` | 사전 파일을 읽고, 그 내용을 배열로 나누어 반환. | 파일 내용 읽고 줄마다 분할한 배열 반환. |
| 2 | `ft_split(buffer, "\n")` | 파일 내용을 줄별로 분할. | `\n`을 기준으로 분할된 문자열 배열 반환. |
5. 숫자 처리 함수들
| 단계 | 함수/작업 | 설명 | 결과 |
|------|-----------------------------------|-------------------------------------------------------------------|--------------------------------------------------------------|
| 1 | `ft_nbr_count_by_three(nbr)` | 숫자 문자열을 3자리씩 나누기 위한 그룹 수를 계산. | 숫자 길이에 맞춰 그룹의 수 반환. |
| 2 | `ft_split_nbr_by_three(nbr, ...)` | 숫자 문자열을 3자리씩 나눈 배열을 생성. | 3자리씩 나누어진 숫자 배열 반환. |
| 3 | `ft_init_zerovalue()` | 3자리 숫자를 표현하기 위한 기본값 `"000"`을 반환. | `"000"` 반환. |
6. 숫자 출력 함수들
| 단계 | 함수/작업 | 설명 | 결과 |
|------|-----------------------------------|-------------------------------------------------------------------|--------------------------------------------------------------|
| 1 | `ft_convert_print(dict, ...)` | 숫자 배열을 처리하여 사전 값에 맞는 단어를 출력. | 각 숫자에 해당하는 단어 출력. |
| 2 | `ft_print_trio(nbr, dict)` | 세 자리 숫자를 묶어서 출력. | 3자리 숫자에 해당하는 단어 출력. |
| 3 | `ft_print_hundred(nbr, dict)` | 100의 자리 숫자 출력. | `100`에 해당하는 단어 출력. |
| 4 | `ft_print_tens(nbr, dict)` | 10의 자리 숫자 출력. | `10`의 자리에 해당하는 단어 출력. |
| 5 | `ft_print_figure(nbr, dict)` | 1의 숫자에 해당하는 단어를 출력. | 해당 숫자의 단어 출력. |
| 6 | `ft_print_exact_value(nbr, dict)` | 딕셔너리에서 서칭하여 해당 number의 문자단어를 출력. | 정확한 값에 해당하는 단어 출력. |
7. 메모리 해제 및 종료
| 단계 | 함수/작업 | 설명 | 결과 |
|------|-----------------------------------|-------------------------------------------------------------------|--------------------------------------------------------------|
| 1 | `ft_free(dict, tab_nbr, nbr, ...)`| 할당된 메모리 해제. | 메모리 해제 후 종료. |
8. 오류 처리
| 단계 | 함수/작업 | 설명 | 결과 |
|------|-----------------------------------|-------------------------------------------------------------------|--------------------------------------------------------------|
| 1 | `ft_error()` | 오류 발생 시 `"Error"` 메시지 출력. | `"Error"` 출력. |
| 2 | `ft_error_dict()` | 사전 관련 오류 발생 시 `"Dict Error"` 메시지 출력. | `"Dict Error"` 출력. |
시퀀스 다이어그램(Mermaid)
0: zéro
1: un
2: deux
3: trois
4: quatre
5: cinq
6: six
7: sept
8: huit
9: neuf
10: dix
11: onze
12: douze
13: treize
14: quatorze
15: quinze
16: seize
17: dix-sept
18: dix-huit
19: dix-neuf
20: vingt
30: trente
40: quarante
50: cinquante
60: soixante
70: soixante-dix
80: quatre-vingts
90: quatre-vingt-dix
100: cent
1000: mille
1000000: million
1000000000: milliard
1000000000000: billion
1000000000000000: trillion
1000000000000000000: quadrillion
1000000000000000000000: quintillion
1000000000000000000000000: sextillion
1000000000000000000000000000: septillion
1000000000000000000000000000000: octillion
1000000000000000000000000000000000: nonillion
1000000000000000000000000000000000000: decillion
1000000000000000000000000000000000000000: undecillon0: zero
1: one
2: two
3: three
4: four
5: five
6: six
7: seven
8: eight
9: nine
10: ten
11: eleven
12: twelve
13: thirteen
14: fourteen
15: fifteen
16: sixteen
17: seventeen
18: eighteen
19: nineteen
20: twenty
30: thirty
40: forty
50: fifty
60: sixty
70: seventy
80: eighty
90: ninety
100: hundred
1000: thousand
1000000: million
1000000000: billion
1000000000000: trillion
1000000000000000: quadrillion
1000000000000000000: quintillion
1000000000000000000000: sextillion
1000000000000000000000000: septillion
1000000000000000000000000000: octillion
1000000000000000000000000000000: nonillion
1000000000000000000000000000000000: decillion
1000000000000000000000000000000000000: undecillion#ifndef FT_HEADER_H
# define FT_HEADER_H
# include <unistd.h>
# include <stdlib.h>
# include <fcntl.h>
# define DEFAULT_DICT "dicts/numbers.dict"
void ft_error(void);
// FT_CHECK_ARGS
int ft_check_args(int argc, char **argv, char **dictpath, char **nbr);
// FT_CHECK_DICT
int ft_check_dict(char *dictpath);
int ft_get_file_size(char *dictpath);
// FT_PROCESS
int ft_process(char *dictpath, char *nbr);
// FT_SPLIT_BY_THREE
int ft_nbr_count_by_three(char *nb);
char **ft_split_nbr_by_three(char *nbr, int size);
// FT_FREE
void ft_free(char **dict, char **tab_nbr, char *nbr, char *zerovalue);
// FT_PRINT1
int ft_print_magnitude(int tab_nbr_size, char **dict);
int ft_print_hundred(char *nbr, char **dict);
int ft_print_tens(char *nbr, char **dict);
int ft_print_trio(char *nbr, char **dict);
// FT_PRINT2
int ft_print_figure(char *nbr, char **dict);
int ft_print_exact_value(char *nbr, char **dict);
// FT_MANAGE_DICT
int ft_word_len(char *str);
int ft_number_len(char *str);
char *ft_get_dict_word(char *str);
char *ft_get_dict_number(char *line);
// FT_SPLIT
char **ft_split(char *str, char *charset);
char *ft_add_word(char *src, int size);
// FT_TOOLS
void ft_putstr(char *str);
void ft_putchar(char c);
int ft_strcmp(char *s1, char *s2);
int ft_strlen(char *str);
// FT_CONDITION
int ft_is_whitespace(char c);
int ft_is_alpha(char c);
int ft_is_lower(char c);
int ft_is_upper(char c);
int ft_is_number(char c);
#endif#include "ft_header.h"
int ft_is_contain_number(char *str)
{
int i;
i = 0;
while (str[i])
{
if (ft_is_number(str[i]))
return (1);
i++;
}
return (0);
}
int ft_check_nbr(char *nbr)
{
int i;
int sign;
if (ft_strlen(nbr) == 0 || !ft_is_contain_number(nbr))
return (0);
i = 0;
while (ft_is_whitespace(nbr[i]))
i++;
sign = 1;
while (nbr[i] == '-' || nbr[i] == '+')
{
if (nbr[i] == '-')
sign *= -1;
i++;
}
if (sign == -1)
return (0);
while (nbr[i])
{
if (nbr[i] < '0' || nbr[i] > '9')
return (0);
i++;
}
return (1);
}
int ft_count_nbr_char_len(char *src, int *index)
{
int i;
int nbr_len;
int only_zero;
i = 0;
only_zero = 1;
while (src[i] && ft_is_whitespace(src[i]))
i++;
while (src[i] == '-' || src[i] == '+' || src[i] == '0')
i++;
*index = i;
nbr_len = 0;
while (src[i] >= '0' && src[i] <= '9')
{
if (src[i] != '0')
only_zero = 0;
nbr_len++;
i++;
}
if (only_zero)
{
*index = i - 1;
return (1);
}
return (nbr_len);
}
char *ft_clean_nbr(char *src)
{
char *dest;
int nbr_len;
int index;
int i;
nbr_len = ft_count_nbr_char_len(src, &index);
dest = malloc(sizeof(char) * (nbr_len + 1));
if (!dest)
return (0);
*dest = 0;
i = 0;
while (src[index])
{
dest[i] = src[index];
i++;
index++;
}
dest[nbr_len] = '\0';
return (dest);
}
int ft_check_args(int argc, char **argv, char **dictpath, char **nbr)
{
if (argc == 3)
{
if (!ft_check_nbr(argv[2]))
return (0);
*dictpath = argv[1];
*nbr = ft_clean_nbr(argv[2]);
if (*nbr == 0)
return (0);
return (1);
}
else if (argc == 2)
{
if (!ft_check_nbr(argv[1]))
return (0);
*dictpath = DEFAULT_DICT;
*nbr = ft_clean_nbr(argv[1]);
if (*nbr == 0)
return (0);
return (1);
}
return (0);
}#include "ft_header.h"
int ft_get_file_size(char *dictpath)
{
char c;
int file;
int count;
file = open(dictpath, O_RDONLY);
if (file == -1)
return (-1);
count = 0;
while (read(file, &c, 1))
count++;
close(file);
return (count);
}
int ft_check_dict(char *dictpath)
{
int file;
int file_size;
file = open(dictpath, O_RDONLY);
if (file == -1)
return (0);
file_size = ft_get_file_size(dictpath);
if (file_size == 0)
return (0);
close(file);
return (1);
}#include "ft_header.h"
void ft_free(char **dict, char **tab_nbr, char *nbr, char *zerovalue)
{
int i;
i = 0;
while (dict[i])
{
free(dict[i]);
i++;
}
free(dict);
i = 0;
while (tab_nbr[i])
{
free(tab_nbr[i]);
i++;
}
free(tab_nbr);
free(nbr);
free(zerovalue);
}#include "ft_header.h"
int ft_word_len(char *str)
{
int i;
i = 0;
while (str[i])
i++;
return (i);
}
int ft_number_len(char *str)
{
int i;
i = 0;
while (ft_is_number(str[i]))
i++;
return (i);
}
char *ft_get_dict_word(char *str)
{
int i;
int j;
int word_len;
char *dest;
i = 0;
while (str[i] != ':')
i++;
if (str[i] == ':')
i++;
while (str[i] == ' ')
i++;
word_len = ft_word_len(str + i);
dest = malloc(sizeof(char) * (word_len + 1));
if (!dest)
return (0);
*dest = 0;
j = 0;
while (str[i])
dest[j++] = str[i++];
dest[word_len] = '\0';
return (dest);
}
char *ft_get_dict_number(char *line)
{
int i;
int nbr_len;
char *nbr;
i = 0;
nbr_len = ft_number_len(line);
nbr = malloc(sizeof(char) * (nbr_len + 1));
if (!nbr)
return (0);
*nbr = 0;
while (ft_is_alpha(line[i]))
{
nbr[i] = line[i];
i++;
}
nbr[nbr_len] = '\0';
return (nbr);
}#include "ft_header.h"
int ft_print_magnitude(int tab_nbr_size, char **dict)
{
char *value;
int size;
int i;
size = ((tab_nbr_size - 1) * 3) + 1;
value = malloc(sizeof(char) * (size + 1));
if (!value)
return (0);
value[0] = '1';
i = 1;
while (i < size)
{
value[i] = '0';
i++;
}
value[size] = '\0';
ft_putchar(' ');
ft_print_exact_value(value, dict);
free(value);
return (1);
}
int ft_print_hundred(char *nbr, char **dict)
{
char *c;
if (nbr[0] == '0')
return (1);
c = malloc(sizeof(char) * 2);
if (!c)
return (0);
*c = nbr[0];
c[1] = '\0';
ft_print_figure(c, dict);
ft_putchar(' ');
ft_print_figure("100", dict);
free(c);
return (1);
}
int ft_print_tens(char *nbr, char **dict)
{
char *d;
while (*nbr == '0')
nbr++;
if (!*nbr)
return (1);
if (*nbr && ft_print_exact_value(nbr, dict))
return (1);
d = malloc(sizeof(char) * 3);
if (!d)
return (0);
*d = nbr[0];
d[1] = '0';
d[2] = '\0';
ft_print_exact_value(d, dict);
free(d);
return (0);
}
int is_french(char **dict)
{
int i;
i = 0;
while (dict[i])
{
if (ft_strcmp(dict[i], "1: un") == 0)
return (1);
i++;
}
return (0);
}
int ft_print_trio(char *nbr, char **dict)
{
int nbr_len;
char *connector;
nbr_len = ft_strlen(nbr);
if (nbr_len == 3)
{
ft_print_hundred(nbr, dict);
if (nbr[0] != '0' && (nbr[1] != '0' || nbr[2] != '0'))
{
if (is_french(dict))
connector = " et ";
else
connector = " and ";
ft_putstr(connector);
}
nbr++;
}
if (ft_print_tens(nbr, dict))
return (1);
nbr++;
ft_putchar('-');
ft_print_figure(nbr, dict);
return (1);
}#include "ft_header.h"
int ft_print_figure(char *nbr, char **dict)
{
int i;
char *dict_word;
char *dict_number;
i = 0;
while (dict[i])
{
dict_word = ft_get_dict_word(dict[i]);
dict_number = ft_get_dict_number(dict[i]);
if (ft_strcmp(nbr, dict_number) == 0)
{
ft_putstr(dict_word);
free(dict_word);
free(dict_number);
return (1);
}
free(dict_word);
free(dict_number);
i++;
}
return (0);
}
int ft_print_exact_value(char *nbr, char **dict)
{
int i;
char *dict_word;
char *dict_number;
i = 0;
while (dict[i])
{
dict_word = ft_get_dict_word(dict[i]);
dict_number = ft_get_dict_number(dict[i]);
if (ft_strcmp(nbr, dict_number) == 0)
{
ft_putstr(dict_word);
free(dict_word);
free(dict_number);
return (1);
}
free(dict_word);
free(dict_number);
i++;
}
return (0);
}#include "ft_header.h"
char **ft_read_file(char *dictpath)
{
char *buffer;
char **split;
int file;
int size;
int bytes_read;
size = ft_get_file_size(dictpath);
if (size < 0)
return (0);
file = open(dictpath, O_RDONLY);
if (file == -1)
return (0);
buffer = malloc(sizeof(char) * (size + 1));
if (!buffer)
{
close(file);
return (0);
}
bytes_read = read(file, buffer, size);
buffer[bytes_read] = '\0';
split = ft_split(buffer, "\n");
free(buffer);
close(file);
return (split);
}
char *ft_init_zerovalue(void)
{
int i;
char *zerovalue;
i = 0;
zerovalue = malloc(sizeof(char) * 4);
if (!zerovalue)
return (0);
*zerovalue = 0;
while (i < 3)
{
zerovalue[i] = '0';
i++;
}
zerovalue[i] = 0;
return (zerovalue);
}
int ft_check_next_value(char **tab_nbr, char *zerovalue, int index)
{
int i;
i = index;
while (tab_nbr[i])
{
if (ft_strcmp(tab_nbr[i], zerovalue) > 0)
return (1);
i++;
}
return (0);
}
int ft_convert_print(
char **dict, char **tab_nbr, int tab_nbr_size, char *zerovalue)
{
int i;
i = 0;
while (tab_nbr[i])
{
if (i > 0 && ft_strcmp(tab_nbr[i], zerovalue) > 0)
ft_putchar(' ');
ft_print_trio(tab_nbr[i], dict);
if ((tab_nbr_size - i > 1) && (ft_strcmp(tab_nbr[i], zerovalue) > 0))
{
ft_print_magnitude(tab_nbr_size - i, dict);
if (ft_check_next_value(tab_nbr, zerovalue, i + 1))
ft_putchar(',');
}
i++;
}
ft_putchar('\n');
return (1);
}
int ft_process(char *dictpath, char *nbr)
{
char **tab_nbr;
char **dict;
char *zerovalue;
int tab_nbr_size;
dict = ft_read_file(dictpath);
tab_nbr_size = ft_nbr_count_by_three(nbr);
tab_nbr = ft_split_nbr_by_three(nbr, tab_nbr_size);
zerovalue = ft_init_zerovalue();
if ((ft_strlen(nbr) == 1) && (nbr[0] == '0'))
{
ft_print_exact_value(nbr, dict);
ft_putchar('\n');
ft_free(dict, tab_nbr, nbr, zerovalue);
return (1);
}
if (ft_convert_print(dict, tab_nbr, tab_nbr_size, zerovalue))
{
ft_free(dict, tab_nbr, nbr, zerovalue);
return (1);
}
ft_free(dict, tab_nbr, nbr, zerovalue);
return (0);
}#include "ft_header.h"
int ft_nbr_count_by_three(char *nb)
{
int len;
len = ft_strlen(nb) / 3;
if (ft_strlen(nb) % 3 != 0)
len++;
return (len);
}
char **ft_split_nbr_by_three(char *nbr, int size)
{
char **trio_nbr;
int i;
int k;
int item_len;
trio_nbr = malloc(sizeof(char *) * (size + 1));
if (!trio_nbr)
return (0);
*trio_nbr = 0;
item_len = ft_strlen(nbr) % 3;
i = 0;
k = 0;
if (item_len == 0)
item_len = 3;
while (nbr[i])
{
trio_nbr[k++] = ft_add_word(nbr + i, item_len);
i += item_len;
if (item_len != 3)
item_len = 3;
}
trio_nbr[size] = 0;
return (trio_nbr);
}#include "ft_header.h"
void ft_error(void)
{
write (2, "Error\n", 6);
}
void ft_error_dict(void)
{
write (2, "Dict Error\n", 11);
}
int main(int argc, char **argv)
{
char *dictpath;
char *nbr;
if (!ft_check_args(argc, argv, &dictpath, &nbr))
{
ft_error();
return (1);
}
if (!ft_check_dict(dictpath))
{
free(nbr);
ft_error_dict();
return (1);
}
if (!ft_process(dictpath, nbr))
{
ft_error_dict();
return (1);
}
return (0);
}에러사항
1. 숫자 0에 대한 처리 (ft_process)
- 문제: "0"이 입력되었을 때 숫자로 출력되지 않는 문제 발생.
- 해결: if ((ft_strlen(nbr) == 1) && (nbr[0] == '0'))를 체크하고 ft_print_exact_value(nbr, dict); 실행.
- 느낀 점: 숫자 변환 시 엣지 케이스("0", "000" 등)를 고려해야 함.
2. 프랑스어 사전 처리 (is_french)
- 문제: 숫자 변환에서 1을 un으로 출력하는 로직이 필요함.
- 해결: is_french() 함수를 추가하여 dict[i] 값이 "1: un"이면 프랑스어 사전인지 판별.
- 느낀 점: 다국어 지원을 고려할 때 구조를 미리 설계하는 것이 중요함.
3. 사전(dictionary) 파싱 (ft_get_dict_number, ft_get_dict_word)
- 문제: str[i]에서 : 이후 공백 처리가 필요함.
- 해결: while (str[i] == ' ') i++;를 추가하여 공백을 스킵.
- 느낀 점: 문자열 파싱 시 예상치 못한 입력을 고려해야 함.
https://github.com/maxkim77/42assignments
GitHub - maxkim77/42assignments
Contribute to maxkim77/42assignments development by creating an account on GitHub.
github.com
'BackEnd > C' 카테고리의 다른 글
| [42경산 본과정] LV1. printf 과제 해결! (3) | 2025.08.03 |
|---|---|
| [42경산 라피신 과제 뽀개기] Ruhs00 - C 언어로 간단한 사각형 테두리 출력하기 (2) | 2025.07.31 |
| [42경산 라피신 과제 뽀개기] C11 과제 - 배열 처리, 조건 탐색, 정렬, 연산 처리 (3) | 2025.07.30 |
| [42경산 라피신 과제 뽀개기] C09 과제 – LIBFT 만들기 Shell, Makefile, split 함수 구현 (1) | 2025.07.29 |
| [42경산 라피신 과제 뽀개기] C08 과제 - 헤더, 매크로, 구조체, 출력까지 한 번에! (2) | 2025.07.28 |



